
Maschinelles Lernen Wie KI die Medizin revolutioniert
Computersysteme können bereits eigenständig Gesundheitsdaten analysieren, daraus lernen und sogar Therapieempfehlungen herleiten. Welche Chancen das für Patient:innen bedeutet und was die Forschung benötigt, um künstliche Intelligenz in der Praxis einzusetzen.
Es gibt Daten, die im Gesundheitssystem ständig anfallen: Blutdruckmessungen, Blutwerte, Sauerstoffsättigung, Ultraschall- und MRT-Aufnahmen. Sie werden ausgewertet, dienen der Diagnose, werden archiviert. Doch was wäre, wenn Computersysteme eigenständig aus den gesammelten Daten eines Patienten lernen würden, daraus sogar neue Erkenntnisse entwickeln? Der Einsatz von künstlicher Intelligenz in der Medizin wird in den nächsten Jahren eines der dominierenden Riesenthemen in der Gesundheitsforschung sein. Wo stehen wir – und welche Perspektiven gibt es?
Der Computer kann „überwacht“ lernen
Künstliche Intelligenz beschreibt die Lernfähigkeit von Computerprogrammen. Für dieses Lernen gibt es zwei Wege. Der erste beschreibt das „überwachte Lernen“: Forschende zeigen dem Computer eine große Zahl ähnlicher Dinge und vermitteln ihm dabei je nach Fragestellung, was richtig oder falsch ist, gesund oder krank. Die Idee dahinter: Wenn der Computer genügend Input bekommt, kann er irgendwann selbst die Unterscheidung treffen. Auf diese Weise kann er den Mediziner:innen nicht nur eine Menge Arbeit abnehmen, es kann auch die Qualität der Diagnose und der Behandlung verbessern.
Was ist maschinelles Lernen?
Audio File
Im Podcast erklärt Julia Schnabel, wie maschinelles Lernen funktioniert und warum der Begriff nicht ideal ist.
Frühe Diagnosen aus Ultraschall-Bildern lernen
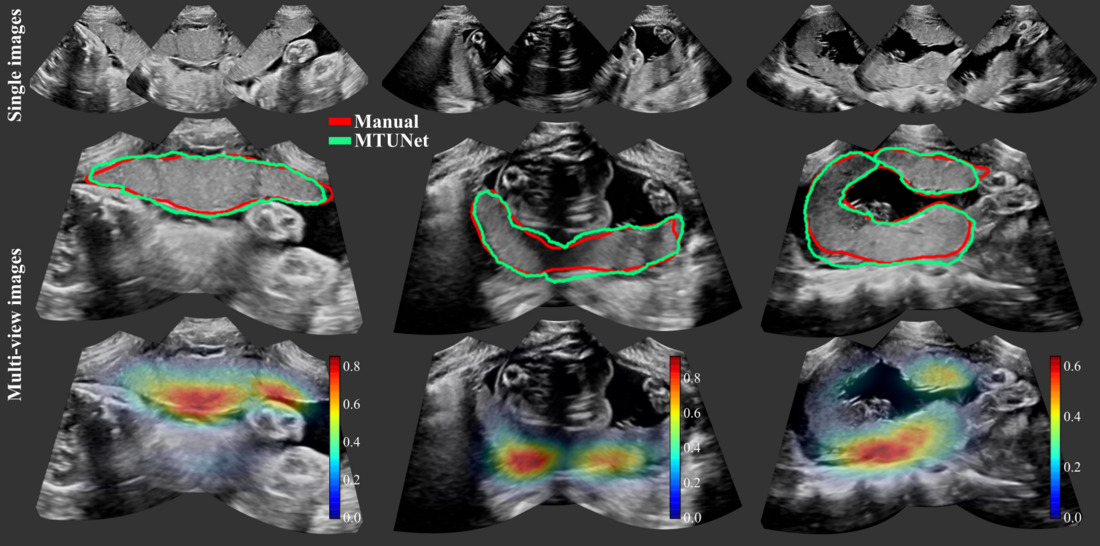
Ein Beispiel aus der Praxis: Julia Schnabel trainiert mit ihrer Forschungsgruppe einen Algorithmus, um die Plazenta bei schwangeren Frauen zu vermessen. Die Plazenta versorgt im Mutterlaib das ungeborene Kind mit Nahrung. Ist diese zu klein, kommt es zu einer Unterversorgung des Ungeborenen. Unter Umständen muss das Kind früher zur Welt gebracht werden, um bleibende Schäden zu verhindern. Weil die Größe der Plazenta und deren Versorgungsmöglichkeit bisher jedoch schwer zu ermitteln ist, achten die Ärzt:innen bei den Kontrolluntersuchungen besonders auf das Wachstum des Kindes – eine mögliche Unterversorgung wird also erst durch ihre Folgewirkung sichtbar.
Der Computer als Sparring-Partner
Der Ansatz hat funktioniert: Das Computerprogramm misst nicht nur die Größe der Plazenta aus. „Wir haben unseren Algorithmus mit weiteren Daten gefüttert, so dass er auch Organe und Körperteile des Ungeborenen erkennt”, erklärt Schnabel. Ziel sei es nicht, die Expert:innen abzulösen, sondern sie zu unterstützen: „Wenn beurteilt werden soll, ob ein Kind früher geholt werden muss oder nicht, dann wird auch in Zukunft immer eine Ärztin oder ein Arzt die Entscheidung treffen.“ Allerdings werden sie dank der Computer-Algorithmen künftig eine bessere Grundlage für ihre Entscheidung haben. Eine kluge künstliche Intelligenz könnte so für die Fachleute in manchen Bereichen eine Art Sparringpartner werden.
Die Plazentavermessung von Schnabels Team ist ein typisches Beispiel dafür, wie künstliche Intelligenz die Medizin voranbringen, in einigen Bereichen auch regelrecht revolutionieren könnte: Der Computer wird mit Daten gefüttert, lernt dazu – und liefert Erkenntnisse, die Menschen neues Wissen bringen.
Data for prevention
Audio File
Julia Schnabel explains how data could help detect diseases earlier.
Digitalisierte Blutanalysen
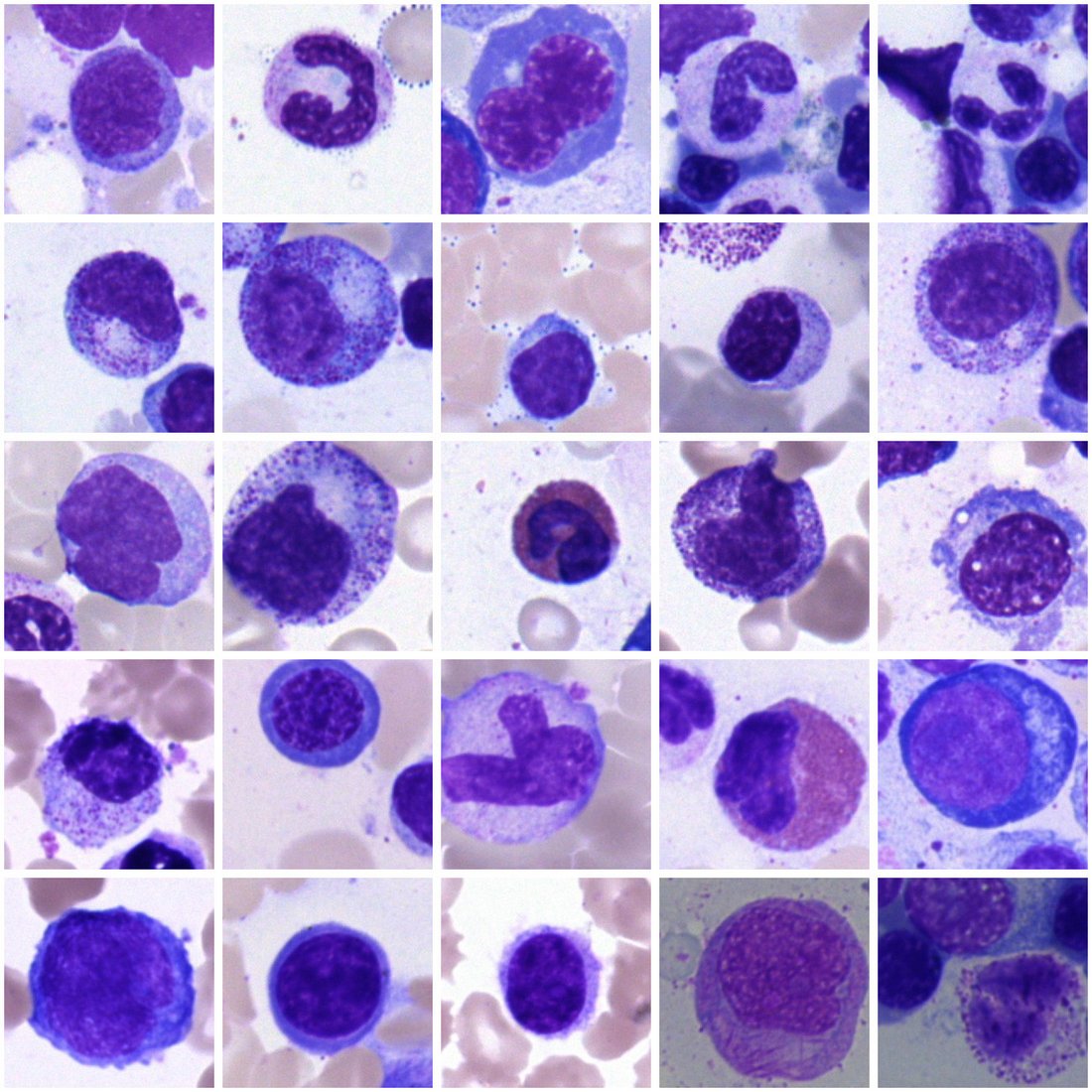
Einen ähnlichen Weg geht Carsten Marr mit seinen Kolleg:innen. Die Forschenden fokussieren sich auf Aufgaben, für welche Fachkräfte normalerweise über Stunden und Tage am Mikroskop sitzen: Bei Verdacht auf Blutkrebs werden in einem sogenannten Blutausstrich mehrere Hundert Zellen von Histolog:innen begutachtet und klassifiziert. Anhand der Ergebnisse zeigt sich, ob und in wie weit die untersuchte Person tatsächlich an einer Erkrankung – zum Beispiel Blutkrebs – leidet und wie eine mögliche Therapie verlaufen kann.
Marr und sein Team haben ein sogenanntes neuronales Netzwerk mit Hunderttausenden von Bildern einzelner weißer Blutzellen und der Information des Zelltyps gefüttert. Und das mit Erfolg: Die Zelltypvorhersagen, die das Programm von Marr auf neuen Bildern liefert, sind ähnlich gut wie die Ergebnisse der Expert:innen. „Ein neuronales Netzwerk ist eine Art Black Box. Es lernt und kann dann selbst neue Zellen klassifizieren, aber im Detail wissen wir nicht, nach welchen Kriterien es entscheidet“, sagt Marr. Deshalb arbeitet er zurzeit daran, diese Kriterien besser zu verstehen: „Die Kriterien können nicht nur hilfreich für die Fachkräfte sein. Es ist uns auch wichtig, den Entscheidungsprozess zu verstehen, um mögliche Fehler und ein Lernen in die falsche Richtung zu vermeiden. Gerade in der Medizin geht es darum, die Black Box des maschinellen Lernens zu nutzen, aber auch zu verstehen, wie sie tickt“, erklärt Marr. Denn erst dann könnten Computer vertrauenswürdige Assistenten werden.
Bildergalerie
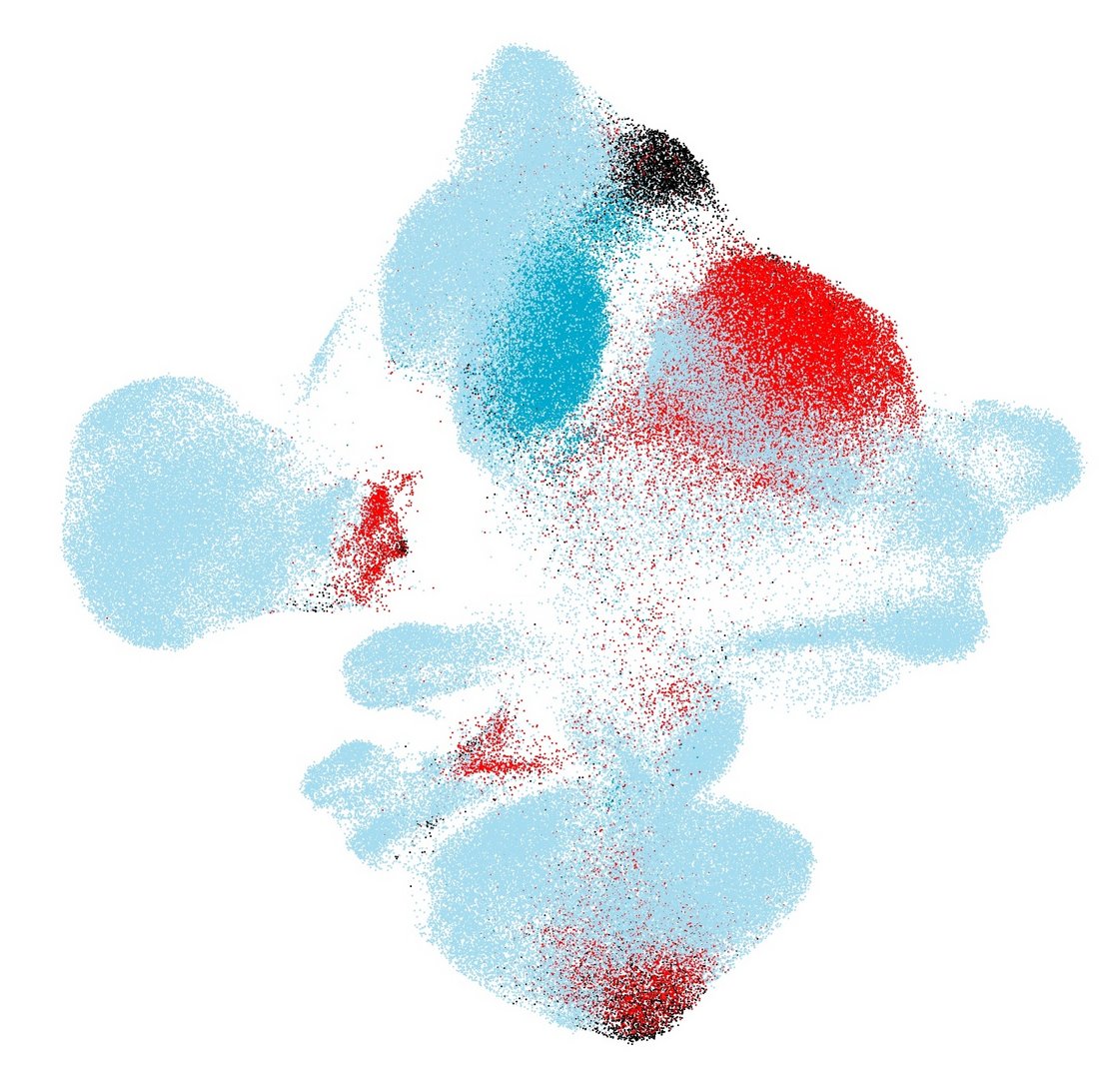
Unüberwachtes Lernen
Es gibt noch einen zweiten Weg, um künstliche Intelligenz anzuwenden: Hier bekommt der Rechner möglichst wenig Hilfestellung, er soll ohne Überwachung lernfähig sein. Der Mathematiker Fabian Theis wendet diese Methode beispielsweise bei der sogenannten Einzelzellanalyse an: Der Computer erhält Daten über einzelne Zellen und ihren Stoffwechsel – und muss darin Muster finden. „Wir sagen ihm dabei nicht, was richtig oder falsch ist, sondern geben ihm nur ein paar Zusatzinformationen. Im Idealfall findet er heraus, welche Gemeinsamkeiten es bei bestimmten Eigenschaften gibt“, erklärt Theis.
Für die Praxis könnte dies bald bedeuten: Der Computer vergleicht den Stoffwechsel der Bauchspeicheldrüsenzellen von Menschen mit und ohne Diabetes – und findet dabei heraus, was bei den defekten Zellen der Diabetes-Patient:innen anders ist. Im nächsten Schritt kann man dann spezifische Medikamente suchen, um die entsprechenden Veränderungen im Zellstoffwechsel zu reparieren.
Daten schwer zugänglich
Um Durchbrüche zu erzielen, benötigt die Forschung enorme Datenmengen. Und die sind vor allem in Deutschland nicht immer verfügbar, weiß auch Julia Schnabel zu berichten: „Ultraschallaufnahmen von der Plazenta lassen sich noch einigermaßen gut gewinnen. Bei vielen anderen Daten ist es in Deutschland allerdings schwierig, die Informationen in einem einheitlichen, vergleichbaren Format zu bekommen.“ Das liege vor allem daran, dass hierzulande das Gesundheitssystem enorm fragmentiert sei. In jedem Bundesland gibt es ein eigenes Gesundheitsministerium, und jedes Krankenhaus sammelt Daten auf seine eigene Weise.
„In Deutschland gebe es eine regelrechte Datenschutzversessenheit“, sagt Carsten Marr. „Was mich wundert, ist die Diskrepanz: Jeder wirft in sozialen Netzwerken mit persönlichen Informationen um sich, aber bei medizinischen Daten, die der Forschung dienen sollen, muss man unzählige Hürden überwinden“, so Marr. Er selbst hält Datenschutz für enorm wichtig – aber dieser allein stünde der Forschung selten im Weg: „Forschende interessieren sich nicht für die Namen, sondern für die Informationen dahinter.“ Trotzdem erleben er und seine Kolleg:innen immer wieder, dass es sehr schwierig ist, an medizinische Daten für die Forschung zu kommen – wenn sie denn überhaupt vorhanden sind.
Und wenn nicht genügend Daten hierzulande für die Forschung zur Verfügung stehen? Für Fabian Theis ist das kein Hindernis: „Man muss derzeit pragmatisch sein, gerade bei Kooperationen mit ausländischen Forschungsinstitutionen kommen die Daten häufig auch von dort“, sagt Theis. Er bleibe optimistisch, dass es in Deutschland in Sachen Datenbereitstellung bald einen Ruck nach vorne gibt. „Ich berate zu dem Thema in zahlreichen politischen Gremien und sehe dort einen echten Willen zum Fortschritt“, sagt Theis. Das wäre eine Win-Win-Win-Situation: für die Forschung, für die Patient:innen – und für den Forschungsstandort Deutschland.
The researchers



Letzte Aktualisierung: Juni 2022.